iOS 卡顿优化
一、原理
1.1 屏幕显示图像原理

首先从过去的 CRT 显示器原理说起。CRT 的电子枪按照上面方式,从上到下一行行扫描,扫描完成后显示器就呈现一帧画面,随后电子枪回到初始位置继续下一次扫描。为了把显示器的显示过程和系统的视频控制器进行同步,显示器(或者其他硬件)会用硬件时钟产生一系列的定时信号。当电子枪换到新的一行,准备进行扫描时,显示器会发出一个水平同步信号(horizonal synchronization),简称 HSync;而当一帧画面绘制完成后,电子枪回复到原位,准备画下一帧前,显示器会发出一个垂直同步信号(vertical synchronization),简称 VSync。显示器通常以固定频率进行刷新,这个刷新率就是 VSync 信号产生的频率。尽管现在的设备大都是液晶显示屏了,但原理仍然没有变。
通常来说,计算机系统中 CPU、GPU、显示器是以上面这种方式协同工作的。CPU 计算好显示内容提交到 GPU,GPU 渲染完成后将渲染结果放入帧缓冲区,随后视频控制器会按照 VSync 信号逐行读取帧缓冲区的数据,经过可能的数模转换传递给显示器显示。
在最简单的情况下,帧缓冲区只有一个,这时帧缓冲区的读取和刷新都会有比较大的效率问题。为了解决效率问题,显示系统通常会引入两个缓冲区,即双缓冲机制。在这种情况下,GPU 会预先渲染好一帧放入一个缓冲区内,让视频控制器读取,当下一帧渲染好后,GPU 会直接把视频控制器的指针指向第二个缓冲器。如此一来效率会有很大的提升。
双缓冲虽然能解决效率问题,但会引入一个新的问题。当视频控制器还未读取完成时,即屏幕内容刚显示一半时,GPU 将新的一帧内容提交到帧缓冲区并把两个缓冲区进行交换后,视频控制器就会把新的一帧数据的下半段显示到屏幕上,造成画面撕裂现象,如下图:
为了解决这个问题,GPU 通常有一个机制叫做垂直同步(简写也是 V-Sync),当开启垂直同步后,GPU 会等待显示器的 VSync 信号发出后,才进行新的一帧渲染和缓冲区更新。这样能解决画面撕裂现象,也增加了画面流畅度,但需要消费更多的计算资源,也会带来部分延迟。
那么目前主流的移动设备是什么情况呢?从网上查到的资料可以知道,iOS 设备会始终使用双缓存,并开启垂直同步。而安卓设备直到 4.1 版本,Google 才开始引入这种机制,目前安卓系统是三缓存+垂直同步。
1.2 卡顿产生的原因
在 VSync 信号到来后,系统图形服务会通过 CADisplayLink 等机制通知 App,App 主线程开始在 CPU 中计算显示内容,比如视图的创建、布局计算、图片解码、文本绘制等。随后 CPU 会将计算好的内容提交到 GPU 去,由 GPU 进行变换、合成、渲染。随后 GPU 会把渲染结果提交到帧缓冲区去,等待下一次 VSync 信号到来时显示到屏幕上。
由于垂直同步的机制,如果在一个 VSync 时间内,CPU 或者 GPU 没有完成内容提交,则那一帧就会被丢弃,等待下一次机会再显示,而这时显示屏会保留之前的内容不变。这就是界面卡顿的原因。
从上面的图中可以看到,CPU 和 GPU 不论哪个阻碍了显示流程,都会造成掉帧现象。所以开发时,也需要分别对 CPU 和 GPU 压力进行评估和优化。
1.3 iOS 渲染循环
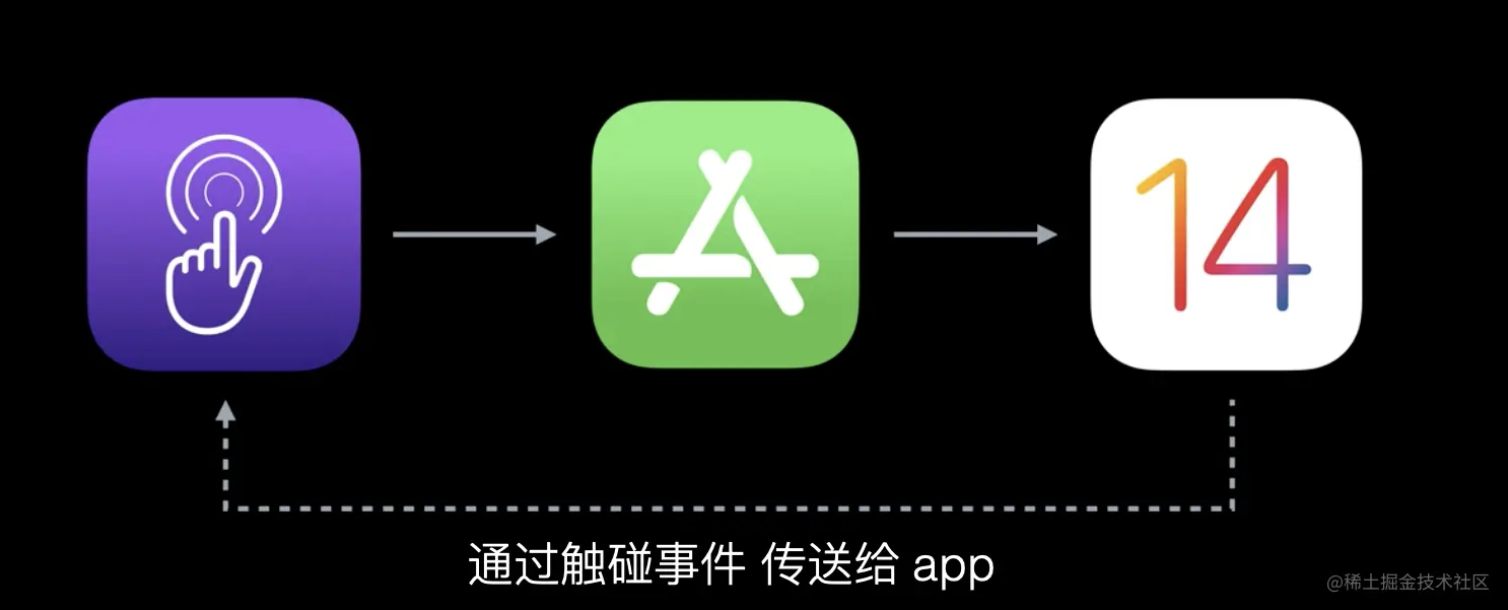
渲染循环是一个连续性的过程。通过触碰事件传送给 app,然后转化到用户界面,向操作系统传送。最终呈现给用户,这就是循环,随着设备的刷新率发生。
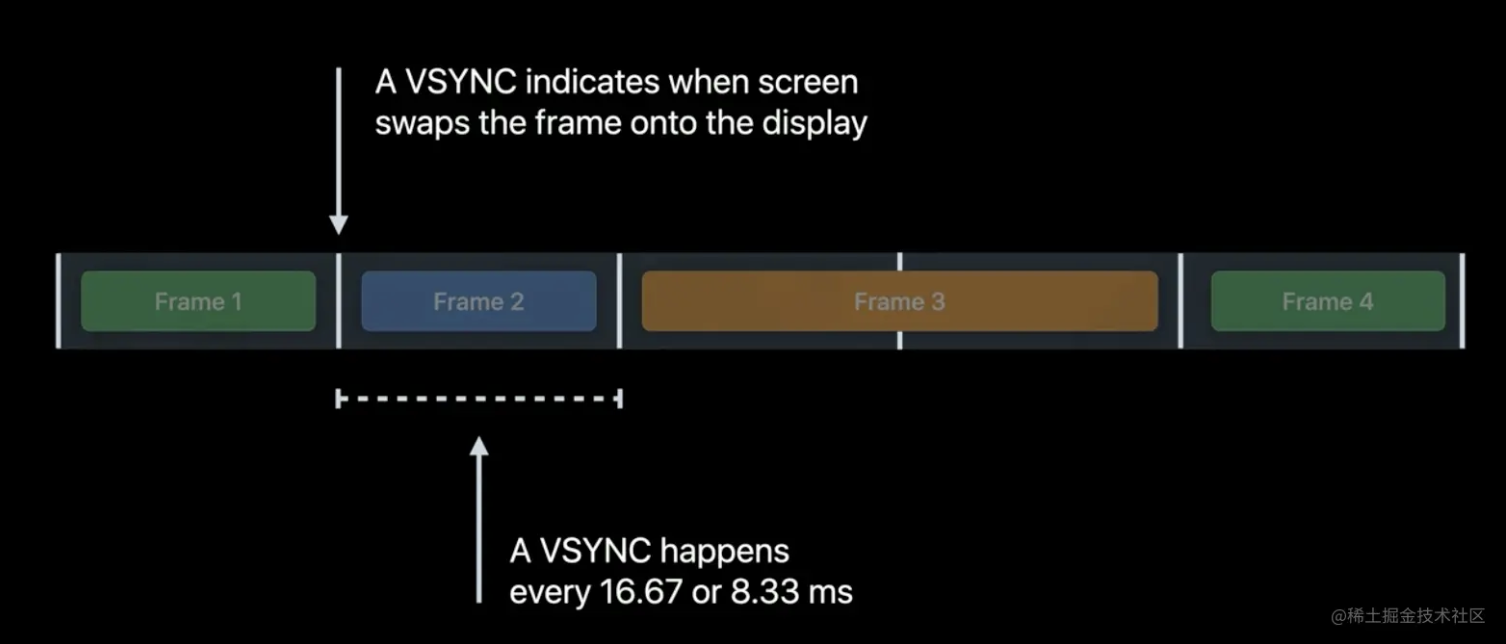
在 iPhone 和 iPad 中,VSync 信号的频率为 60Hz,在 iPad Pro 中为 120Hz。我们以 iPhone 为例,这意味着每 16.67 毫秒(或者 8.34ms),就可以显示一个新帧。
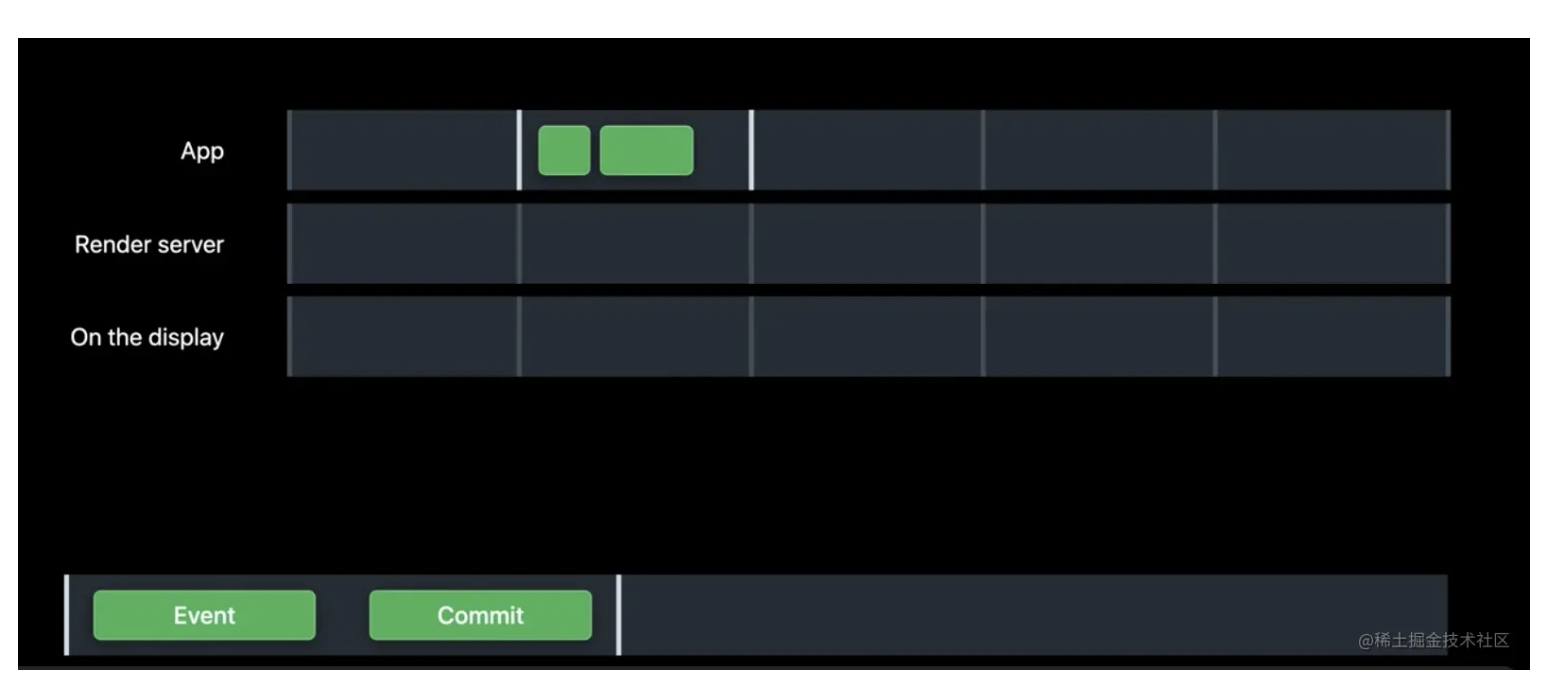
整个渲染循环由五个阶段组成:事件阶段(Event)、提交阶段、渲染准备、渲染执行、展示阶段。
在提交或渲染或展示阶段,如果花费的时间超过一帧,就会造成卡顿。
1.3.1 事件准备
在这个阶段,App 处理触碰事件或者 Timer 等其他事件,决定是否需要改变 View 的 backgroundColor、frame 等属性。

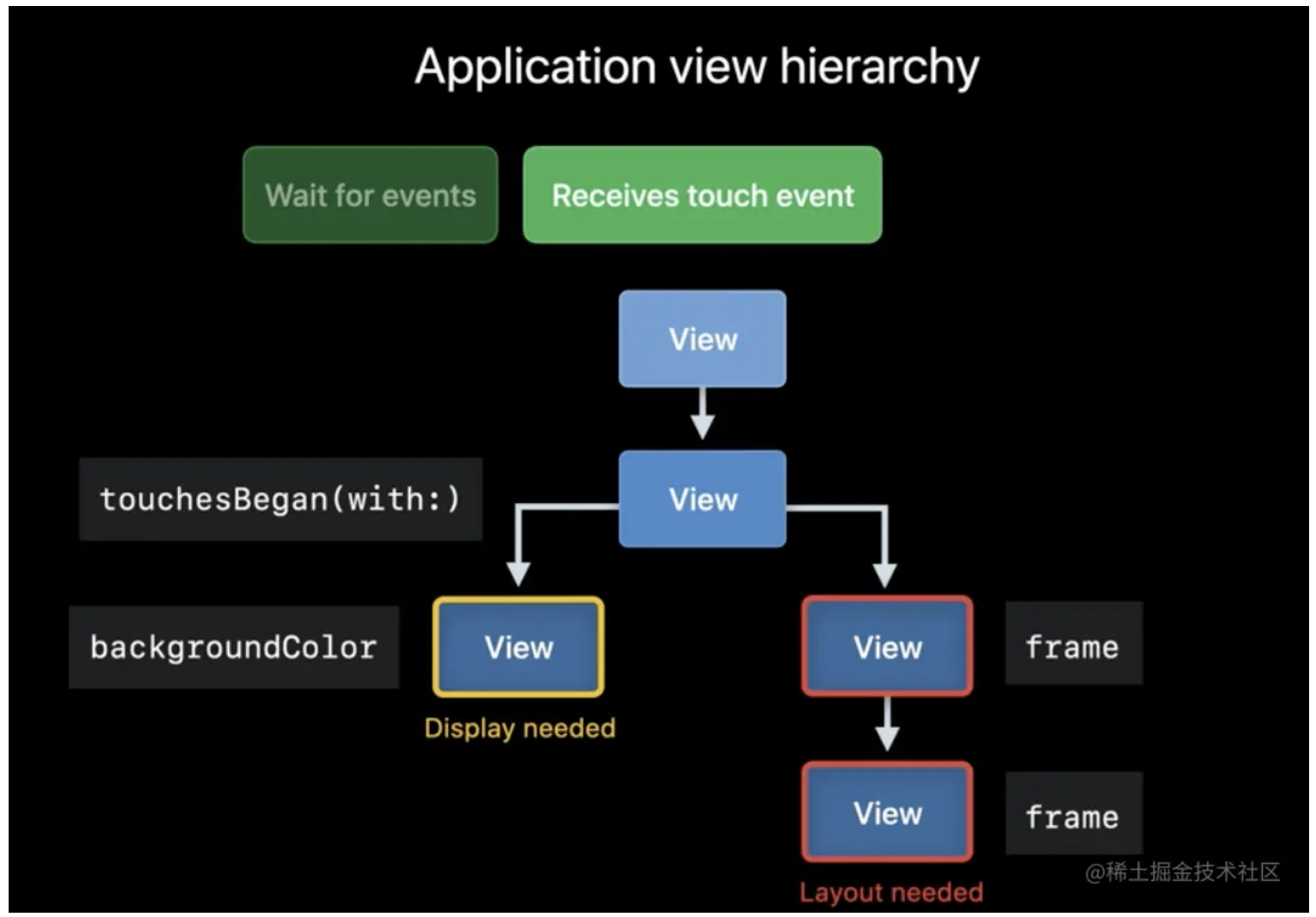
1.3.2 提交阶段
在事件准备之后的下一个渲染循环,系统记录这些子视图将需要某个布局或显示,在提交事务时,这些需要某个显示或布局的视图,会通过调用 drawRect 或 layoutSubviews 来进行相应的更新。更新之后,app 向渲染服务器提交渲染命令。
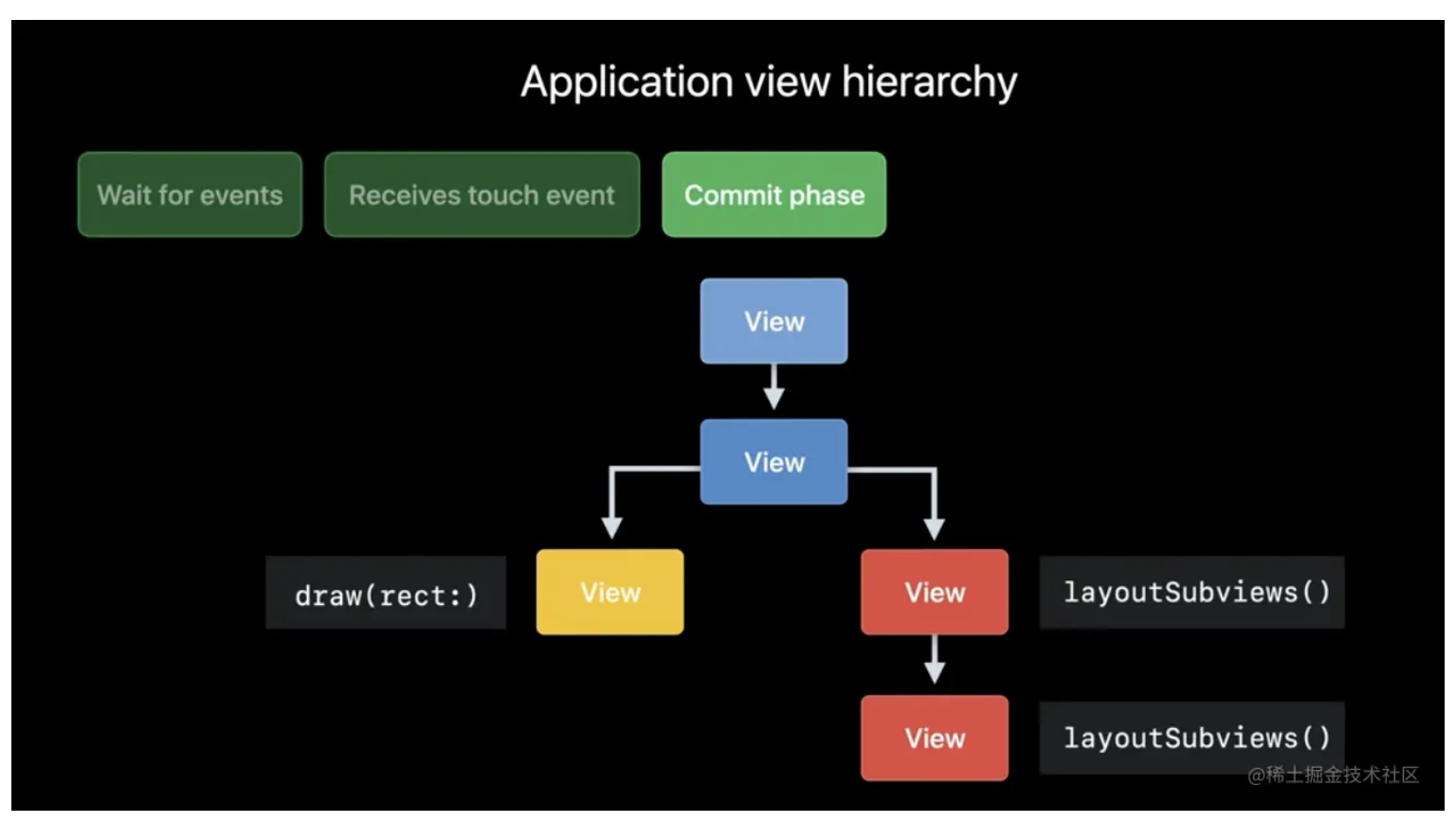
提交事务的 4 个步骤:Layout(布局)、Display(展示)、Prepare(筹备)、Commit(提交)。
Layout(布局阶段)
layoutSubviews 在 view 需要布局的时候会调用,以下情况需要重新布局:
- Positioning views(位置改变),例如,frame、bounds、transform 属性改变,会重新布局
- 添加或者删除 view
- 显示调用
setNeedsLayout()
Display(展示阶段)
需要更新内容的视图,都会调用 draw(rect:) 方法。以下情况会调用 draw(rect:) 方法:
- 添加了重写
draw(rect:)方法的视图 - 直接调用了
setNeedsDisplay()方法,以表明需要展示
Prepare(筹备阶段)
- 对未解码的图片,进行解码
- 若某个图像的颜色格式图形处理器无法直接使用,将会进行转换,这样会消耗很多的内存
Commit (提交阶段)
- 视图层次结构将被递归打包,并通过 IPC 发送到渲染服务器
1.3.3 渲染准备
通过绘制一个有阴影的示例,来讲解下绘制过程。

在渲染准备阶段,渲染服务器会逐层编译一系列绘图命令,使 GPU 能从后向前绘制用户界面。
渲染服务器使用中序遍历渲染整个管道,先渲染根节点,然后渲染左节点,然后渲染右节点。
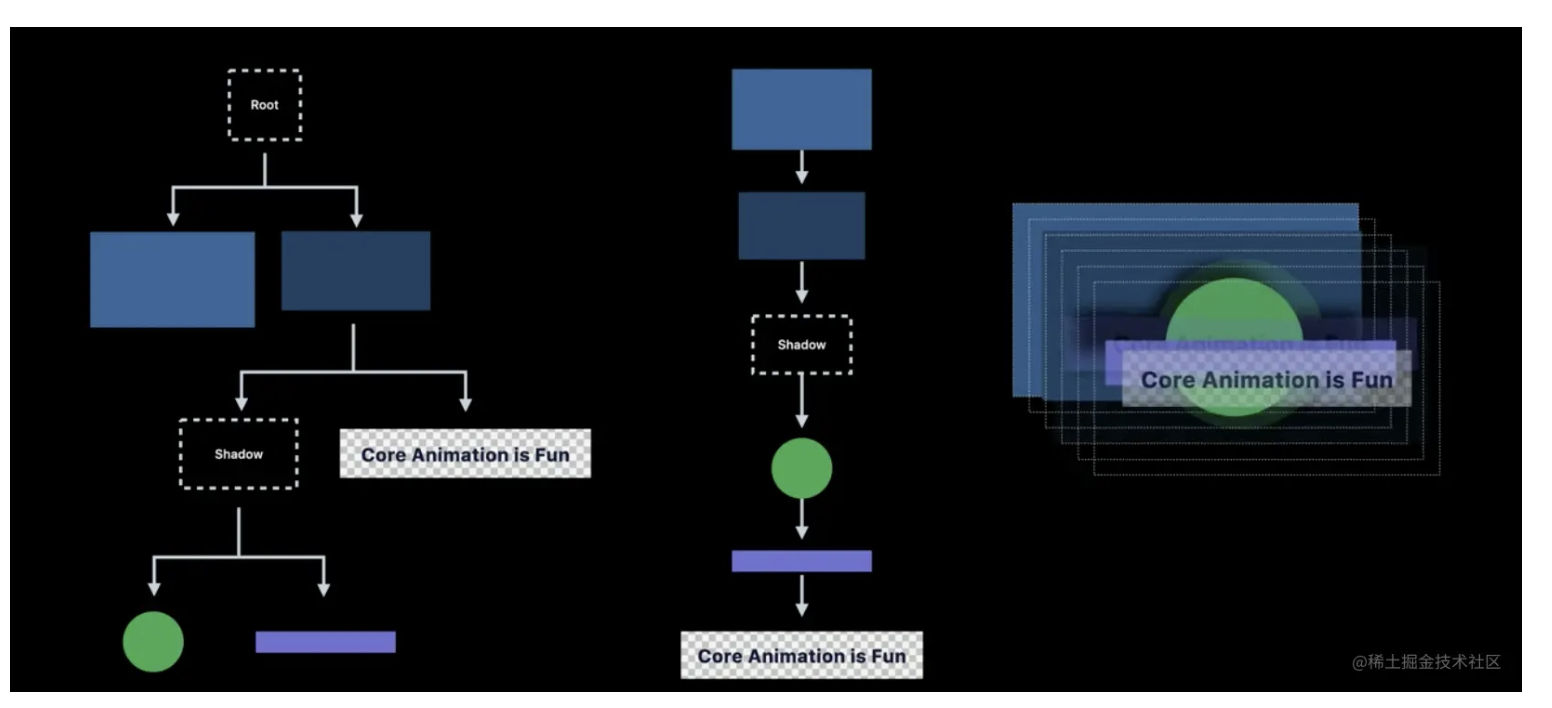
1.3.4 渲染执行

在渲染执行阶段,按照这个管道的顺序进行绘制:
- 先绘制蓝色
- 绘制深蓝色
- 绘制阴影
阴影的形状由它下面的两个层定义,因此 GPU 不知道用什么形状来绘制阴影,但如果先绘制圆形和长条,那么阴影会用黑色遮挡它们,看起来会不正确,此时,GPU 必须切换到不同的纹理,以确定阴影的形状,这种情况,我们称之为离屏渲染,在新开辟的纹理中,加下面的层复制过来,确定阴影的形状,阴影渲染完成后,将那个离屏纹理复制到最终纹理中。
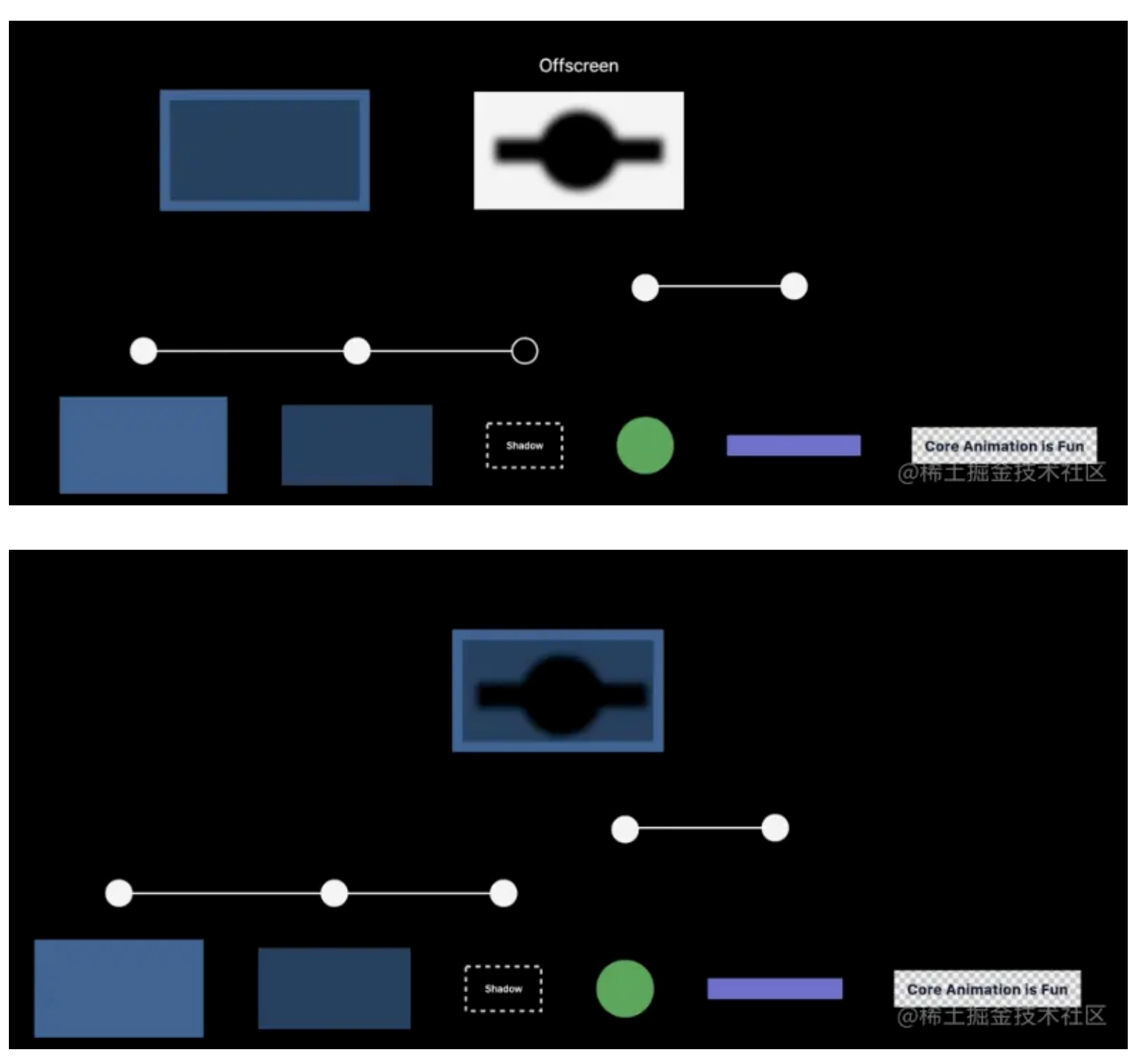
离屏渲染:GPU 先在其他地方渲染一个图层,然后再将其复制过来,我们称之为离屏通道(Offscreen Pass)。
- 绘制圆形和长方形和文字
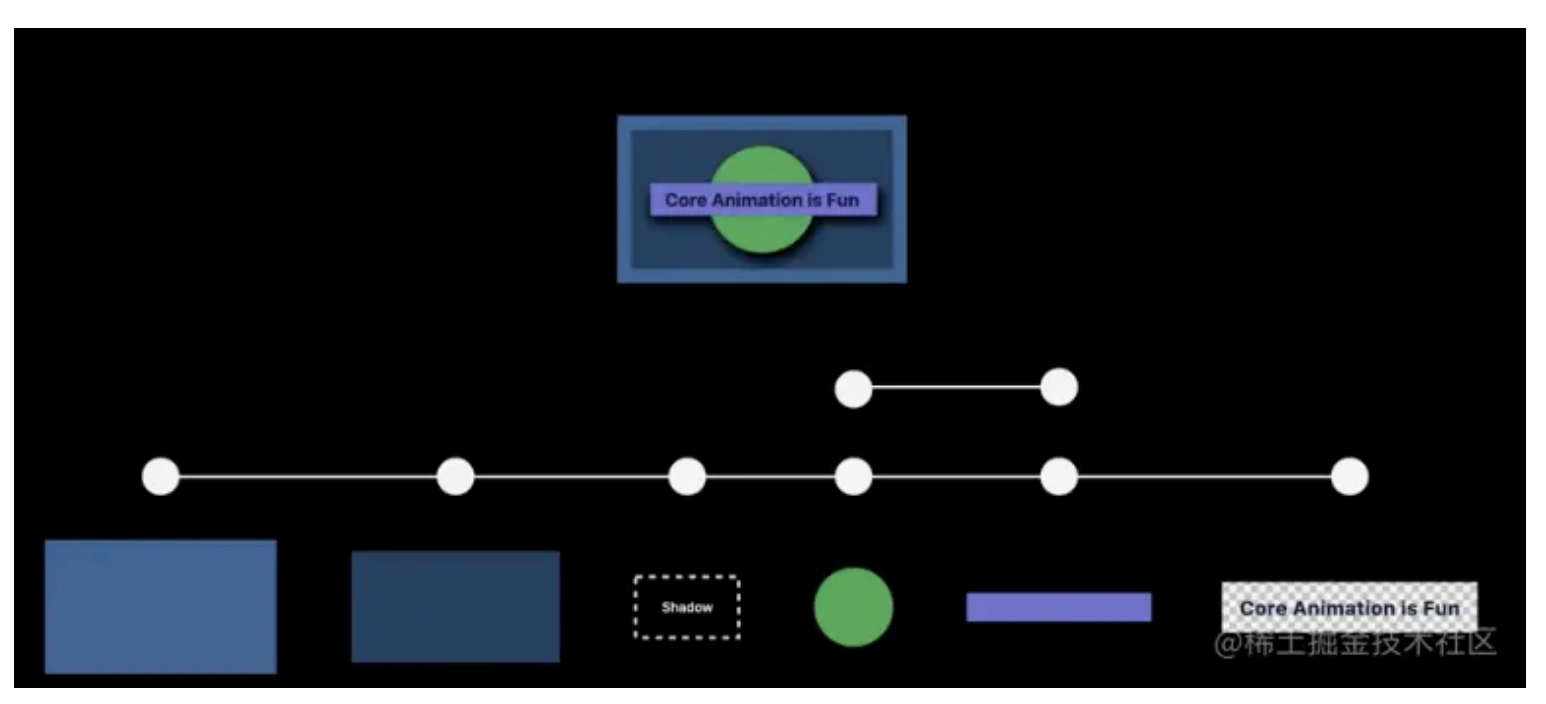
1.3.5 展示阶段
展示阶段将渲染好的内容显示到屏幕上,完成整个渲染循环。
1.4 App 卡顿等级 – 卡顿时间比
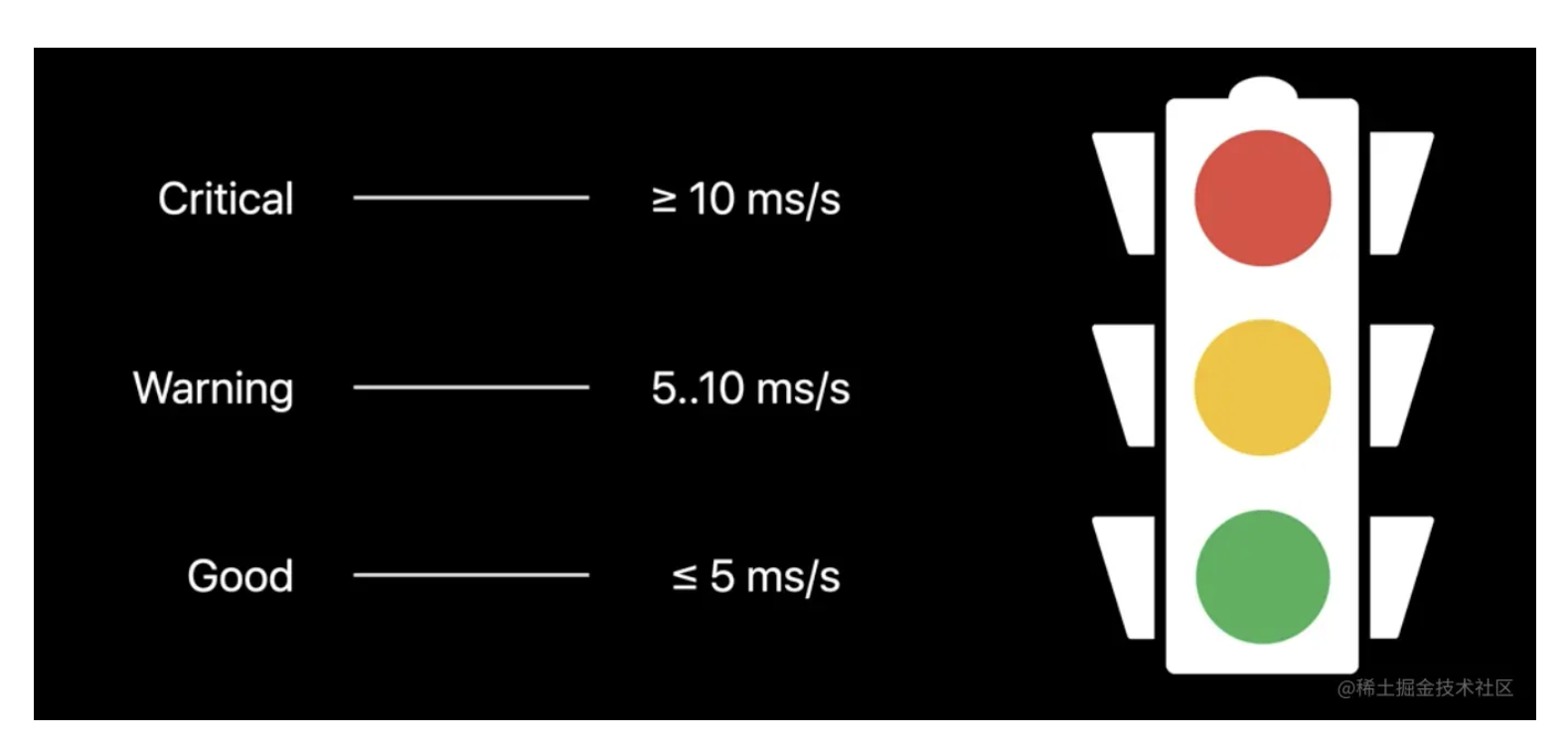
卡顿时间比 = 卡顿时长 / 运行时间
在 Apple 的官方建议中,使用卡顿时间比来衡量卡顿的严重等级。卡顿时间比大于等于 1% 即属于严重卡顿,0.5%~1% 属于警告卡顿,小于 0.5% 属于运行流畅。
1.5 操作卡顿等级
操作的卡顿等级根据卡顿阻塞时间的长短进行了 3 个等级的划分:
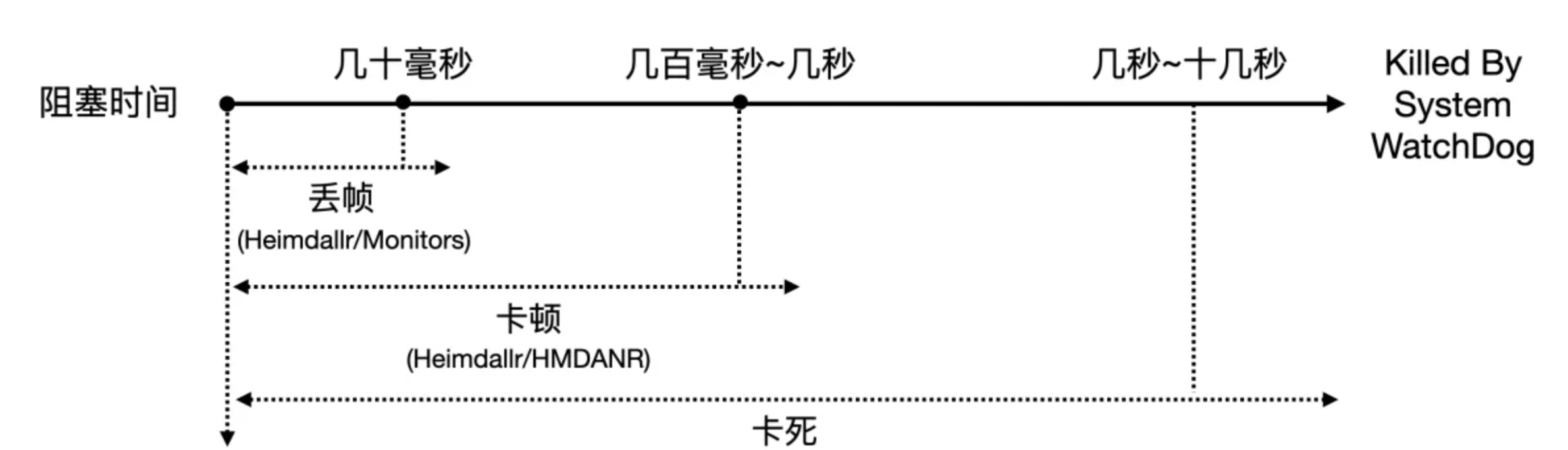
- 丢帧:动画、滑动列表不流畅,一般为十几至几十毫秒的级别
- 卡顿:短时间操作无反应,恢复后能继续使用,从几百毫秒至几秒,暂定 400ms
- 卡死:长时间无反应,直至被系统杀死,通过线上收集数据,最少为 5s
其中卡死是最损害用户体验的,因为卡死不仅仅造成了类似于崩溃的闪退,app 在相当长的一段时间对用户还是不可用的。
二、线下监控方案
使用真机,发布版本进行卡顿检测,最好选用低端机型,这样比较容易发现问题。
2.1 Xcode
2.1.1 渲染选项
使用方式:Xcode -> Debug -> View Debugging -> Rendering
-
Color Blended Layers – 这个选项基于渲染程度对屏幕中的混合区域进行绿到红的高亮(也就是多个半透明图层的叠加)。由于重绘的原因,混合对 GPU 性能会有影响,同时也是滑动或者动画帧率下降的罪魁祸首之一。
-
Color Hits Green and Misses Red – 当使用
shouldRasterize属性的时候,耗时的图层绘制会被缓存,然后当做一个简单的扁平图片呈现。当缓存再生的时候这个选项就用红色对栅格化图层进行了高亮。如果缓存频繁再生的话,就意味着栅格化可能会有负面的性能影响了。 -
Color Copied Images – 有时候寄宿图片的生成意味着 Core Animation 被强制生成一些图片,然后发送到渲染服务器,而不是简单的指向原始指针。这个选项把这些图片渲染成蓝色。复制图片对内存和 CPU 使用来说都是一项非常昂贵的操作,所以应该尽可能的避免。
-
Color Immediately – 通常 Core Animation Instruments 以每毫秒 10 次的频率更新图层调试颜色。对某些效果来说,这显然太慢了。这个选项就可以用来设置每帧都更新(可能会影响到渲染性能,而且会导致帧率测量不准,所以不要一直都设置它)。
-
Color Misaligned Images – 这里会高亮那些被缩放或者拉伸以及没有正确对齐到像素边界的图片(也就是非整型坐标)。这些中的大多数通常都会导致图片的不正常缩放,如果把一张大图当缩略图显示,或者不正确地模糊图像,那么这个选项将会帮你识别出问题所在。
-
Color Offscreen-Rendered Yellow – 这里会把那些需要离屏渲染的图层高亮成黄色。这些图层很可能需要用
shadowPath或者shouldRasterize来优化。 -
Color OpenGL Fast Path Blue – 这个选项会对任何直接使用 OpenGL 绘制的图层进行高亮。如果仅仅使用 UIKit 或者 Core Animation 的 API,那么不会有任何效果。如果使用 GLKView 或者 CAEAGLLayer,那如果不显示蓝色块的话就意味着你正在强制 CPU 渲染额外的纹理,而不是绘制到屏幕。
-
Flash Updated Regions – 这个选项会对重绘的内容高亮成黄色(也就是任何在软件层面使用 Core Graphics 绘制的图层)。这种绘图的速度很慢。如果频繁发生这种情况的话,这意味着有一个隐藏的 bug 或者说通过增加缓存或者使用替代方案会有提升性能的空间。
2.1.2 其它
- 模拟器离屏渲染检测:
Debug -> Color Off-screen Rendered

- 优化建议:
Debug View Hierarchy,Editor -> Show Optimization Opportunities,Xcode 会显示优化建议
2.2 Instruments
2.2.1 Animation Hitches
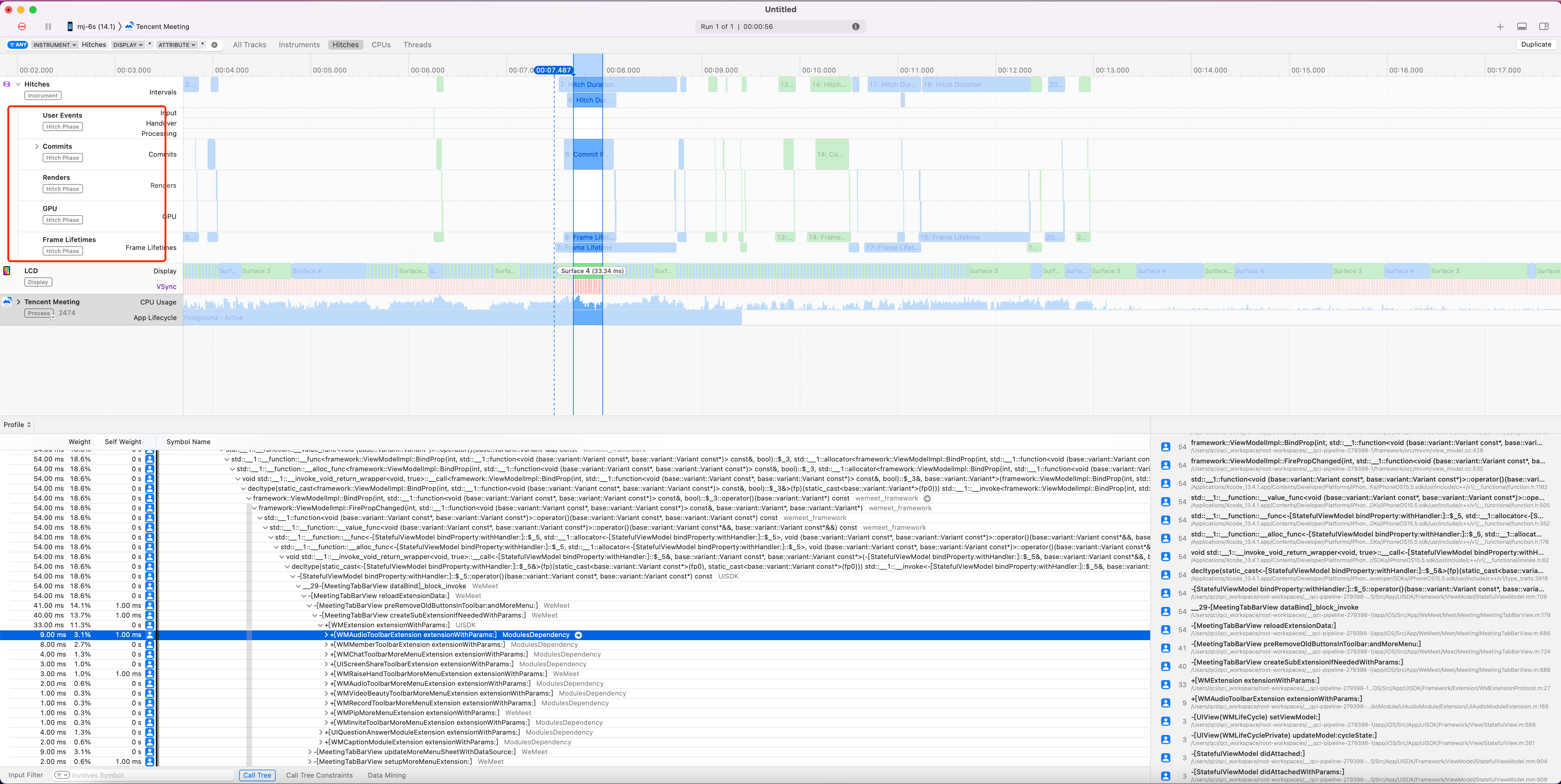
Animation Hitches 是 Xcode Instruments 中用于检测动画卡顿的工具,可以帮助识别导致动画不流畅的原因。
2.2.2 OpenGL ES(已废弃)
侧栏的右边是一系列有用的工具。其中和 Core Animation 性能最相关的是如下几点:
-
Renderer Utilization – 如果这个值超过了 ~50%,就意味着你的动画可能对帧率有所限制,很可能因为离屏渲染或者是重绘导致的过度混合。
-
Tiler Utilization – 如果这个值超过了 ~50%,就意味着你的动画可能限制于几何结构方面,也就是在屏幕上有太多的图层占用了。
三、线上监控方案
iOS 中的 3 种卡顿检测方案:
3.1 监控 FPS
一般来说,我们约定 60FPS 即为流畅。那么反过来,如果 App 在运行期间出现了掉帧,即可认为出现了卡顿。
监控 FPS 的方案几乎都是基于 CADisplayLink 实现的。简单介绍一下 CADisplayLink:CADisplayLink 是一个和屏幕刷新率保持一致的定时器,一旦 CADisplayLink 以特定的模式注册到 runloop 之后,每当屏幕需要刷新的时候,runloop 就会调用 CADisplayLink 绑定的 target 上的 selector。可以通过向 RunLoop 中添加 CADisplayLink,根据其回调来计算出当前画面的帧数。
#import "FPSMonitor.h"
#import <UIKit/UIKit.h>
@interface FPSMonitor ()
@property (nonatomic, strong) CADisplayLink* link;
@property (nonatomic, assign) NSInteger count;
@property (nonatomic, assign) NSTimeInterval lastTime;
@end
@implementation FPSMonitor
- (void)beginMonitor {
_link = [CADisplayLink displayLinkWithTarget:self selector:@selector(fpsInfoCaculate:)];
[_link addToRunLoop:[NSRunLoop mainRunLoop] forMode:NSRunLoopCommonModes];
}
- (void)fpsInfoCaculate:(CADisplayLink *)sender {
if (_lastTime == 0) {
_lastTime = sender.timestamp;
return;
}
_count++;
double deltaTime = sender.timestamp - _lastTime;
if (deltaTime >= 1) {
NSInteger FPS = _count / deltaTime;
_lastTime = sender.timestamp;
_count = 0;
NSLog(@"FPS: %li", (NSInteger)ceil(FPS + 0.5));
}
}
@end
FPS 监控的优缺点:
- 优点:直观,小手一划后 FPS 下降了,说明页面的某处有性能问题
- 缺点:只知道这是页面的某处,不能准确定位到具体的堆栈
3.2 监控 RunLoop
iOS App 基于 RunLoop 消息循环机制运行,有消息时进行处理,没有消息时进入休眠状态。
RunLoop 同时提供了 6 种运行状态通知接口,这 6 种状态分别是:
typedef CF_OPTIONS(CFOptionFlags, CFRunLoopActivity) {
kCFRunLoopEntry = (1UL << 0), // 即将进入 RunLoop
kCFRunLoopBeforeTimers = (1UL << 1), // 即将处理 Timers
kCFRunLoopBeforeSources = (1UL << 2), // 即将处理 Sources
kCFRunLoopBeforeWaiting = (1UL << 5), // 即将进入休眠
kCFRunLoopAfterWaiting = (1UL << 6), // 刚从休眠中唤醒
kCFRunLoopExit = (1UL << 7), // 即将退出 RunLoop
kCFRunLoopAllActivities = 0x0FFFFFFFU // 以上所有状态
};
整个 runloop 消息处理流程如下:
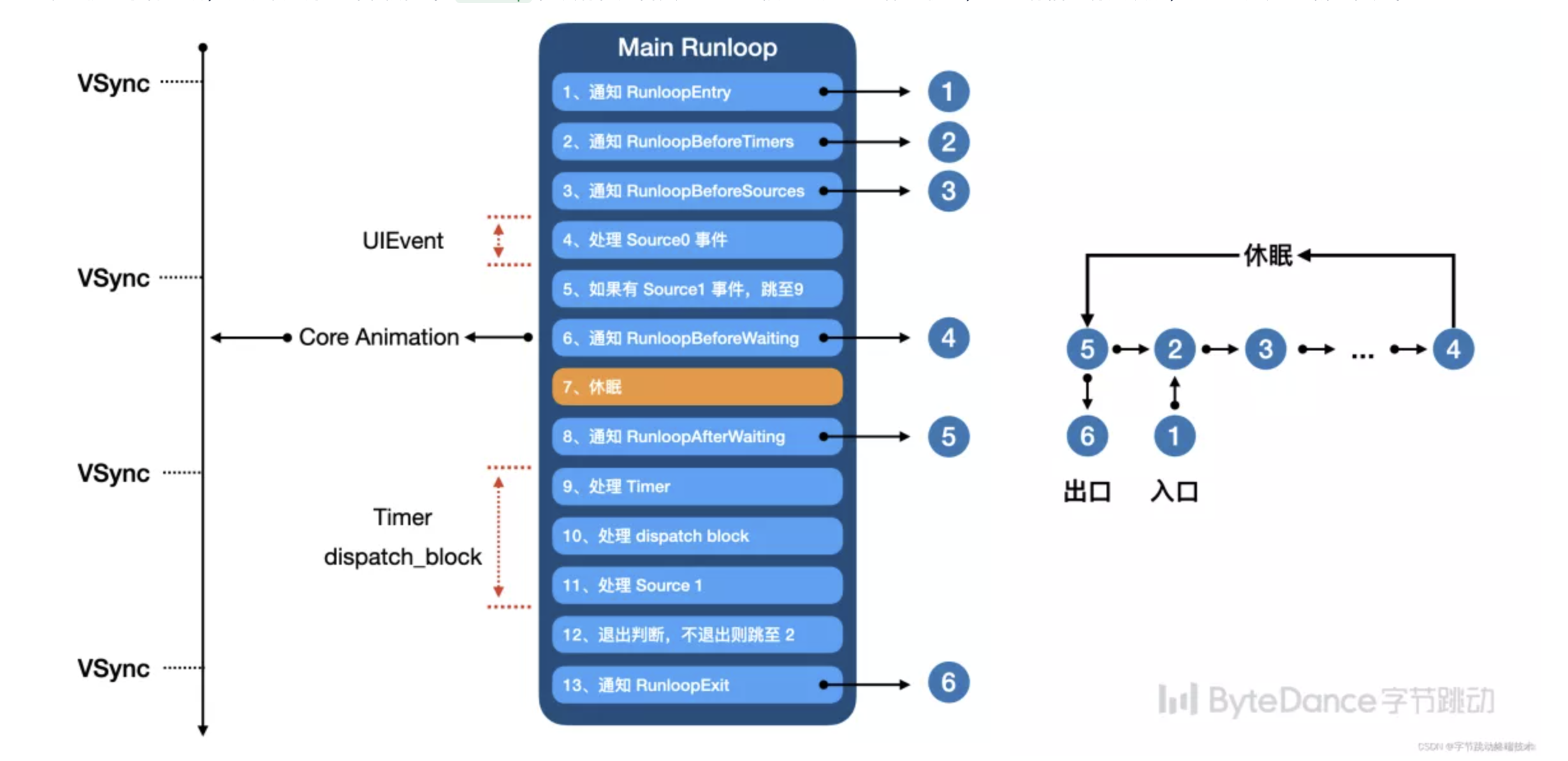
RunLoop 在 BeforeSources 和 AfterWaiting 后会进行任务的处理。观察线程在收到 runloop 线程处于该状态之后设置超时时间,若超时后 RunLoop 的状态仍为 BeforeSources 或 AfterWaiting,表明此时 RunLoop 仍然在处理任务,主线程发生了卡顿。
参考监控代码如下:
- (void)start {
if (self.runing) {
return;
}
self.runing = YES;
CFIndex order[2] = {0, LONG_MAX};
for (int i=0; i<2; ++i) {
if (self.ctx[i].ref != NULL) {
continue;
}
__weak typeof(self) weakSelf = self;
CFRunLoopObserverRef ref = CFRunLoopObserverCreateWithHandler(
kCFAllocatorDefault,
kCFRunLoopAllActivities,
YES,
order[i],
^(CFRunLoopObserverRef observer, CFRunLoopActivity activity) {
__strong typeof(self) strongSelf = weakSelf;
if (strongSelf != nil) {
if (observer == strongSelf.ctx[0].ref) {
strongSelf.ctx[0].activity = activity;
} else {
strongSelf.ctx[1].activity = activity;
}
dispatch_semaphore_signal(strongSelf.semaphore);
}
}
);
CFRunLoopAddObserver(CFRunLoopGetMain(), ref, kCFRunLoopCommonModes);
self.ctx[i].ref = ref;
}
[self startCheckHangup];
LOG_INFO("hangup start observer");
}
- (void)startCheckHangup {
__weak typeof(self) weakSelf = self;
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
LOG_INFO("hangup start check hangup");
while (YES) {
__strong typeof(self) strongSelf = weakSelf;
if (strongSelf == nil) {
break;
}
if (!strongSelf.runing) {
break;
}
[strongSelf checkHangup];
}
LOG_INFO("hangup stop check hangup");
});
}
- (void)checkHangup {
static CFAbsoluteTime adjustInterval = (float)self.config.checkInterval / 1000;
dispatch_time_t timeout = dispatch_time(DISPATCH_TIME_NOW, self.config.checkInterval*NSEC_PER_MSEC);
long semaphoreWait = dispatch_semaphore_wait(self.semaphore, timeout);
if (semaphoreWait != 0) {
if (self.ctx[0].activity == kCFRunLoopBeforeSources
|| self.ctx[0].activity == kCFRunLoopAfterWaiting
|| self.ctx[1].activity == kCFRunLoopBeforeSources
|| self.ctx[1].activity == kCFRunLoopAfterWaiting) {
// 发生卡顿
++self.timeoutCount;
}
} else if (self.timeoutCount > 0) {
// 卡顿结束
self.timeoutCount = 0;
}
}
3.2.1 高可用卡顿检测
卡顿监控有时会出现失效的情况,基本原因是因为 runloop 观察者有时会在接收到事件通知的时候,做一些额外的 UI 操作,比如 UITableView -tableView:didSelectRowAtIndexPath 函数实现是在接收到 kCFRunLoopBeforeWaiting 通知之后才开始执行的,如果卡顿监控的观察者早于 UITableView 观察者接收到这个通知,就无法检测到 UITableView 的卡顿操作。
针对这种场景,可以通过添加两个 runloop 的卡顿监控观察者,确保一个最先接收到事件通知,一个最后接收到事件通知,这样就可以完美解决卡顿检测有时失效的问题。
3.2.2 Core Animation 观察者模式
Core Animation 在 RunLoop 中注册了一个 Observer,监听了 BeforeWaiting 和 Exit 事件。这个 Observer 的优先级是 2000000,低于常见的其他 Observer。
当一个触摸事件到来时,RunLoop 被唤醒,App 中的代码会执行一些操作,比如创建和调整视图层级、设置 UIView 的 frame、修改 CALayer 的透明度、为视图添加一个动画;这些操作最终都会被 CALayer 捕获,并通过 CATransaction 提交到一个中间状态去(CATransaction 的文档略有提到这些内容,但并不完整)。
当上面所有操作结束后,RunLoop 即将进入休眠(或者退出)时,关注该事件的 Observer 都会得到通知。这时 CA 注册的那个 Observer 就会在回调中,把所有的中间状态合并提交到 GPU 去显示;如果此处有动画,CA 会通过 DisplayLink 等机制多次触发相关流程。
3.2.3 卡顿
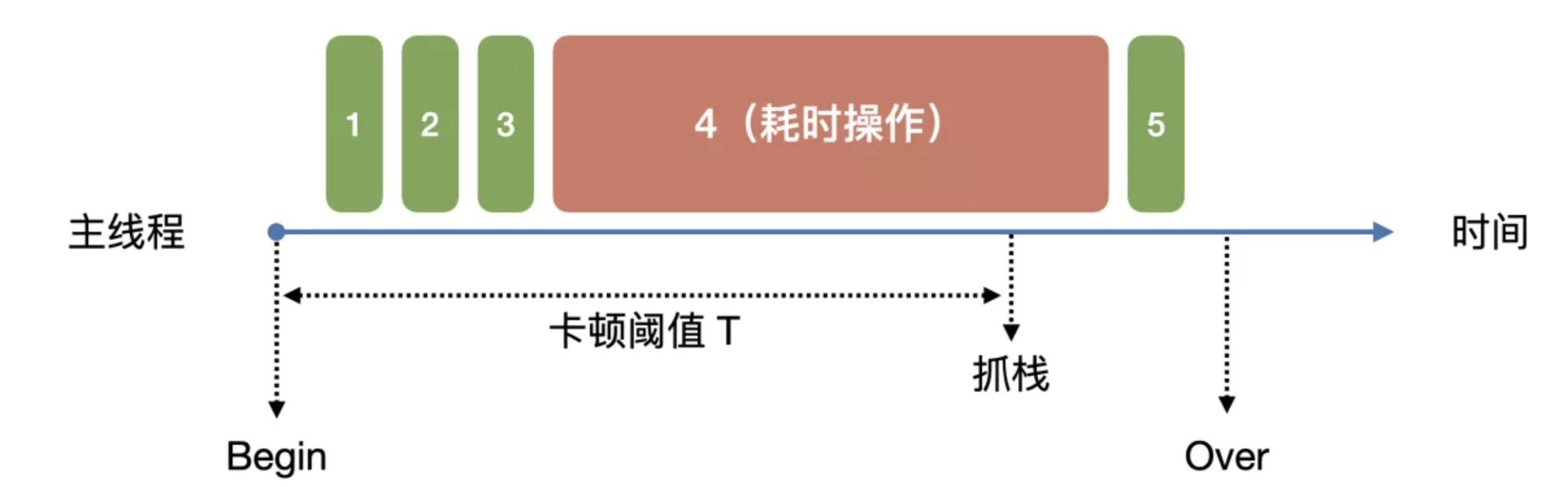
卡顿操作的特点在于主线程的阻塞是暂时性和可恢复性。因此我们要获取卡顿持续的时间,用来评估卡顿问题的严重性。我们预先设定一个卡顿时间的阈值 T,当主线程阻塞的时间超过该阈值,则会触发主线程的堆栈捉取,监听线程继续等待主线程直至恢复,并计算卡顿的总时间,最后把卡顿总时间和卡顿堆栈上报后台。如果主线程超过一定的时间(比如 5 秒)一直无法恢复,则会触发卡死检测逻辑。
3.2.4 卡死
iOS 会对 APP 的主线程进行监控,一旦主线程阻塞时间超过一定的阀值(卡顿多久会被系统强杀),iOS 就会强制杀死当前进程,并且 app 不会得到任何通知。因此 app 需要在系统强杀之前,提前检测到自身的卡死的状态,并采样卡死堆栈。
卡死场景并不一定是死锁或者死循环导致的,也有可能是执行了某些特别的耗时操作。由于可能存在死锁的场景,只采集主线程的堆栈有时是不足于定位问题的,所以卡死场景需要采集所有线程的堆栈。
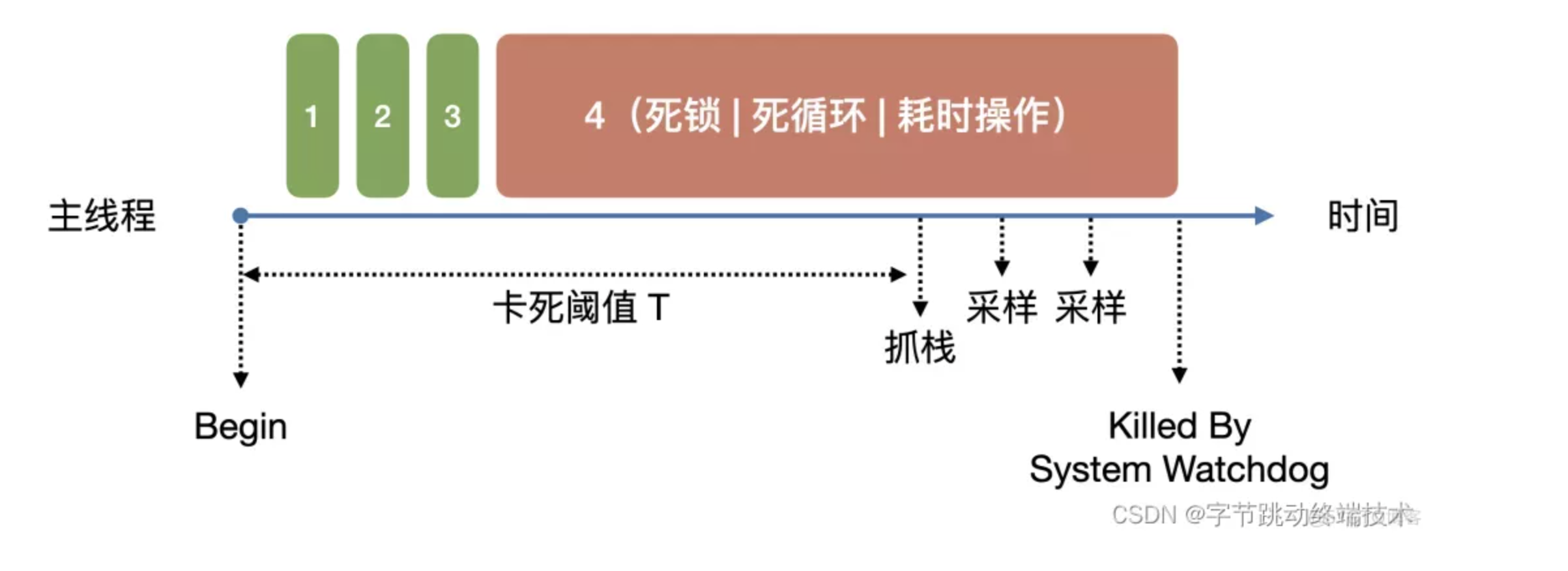
3.2.5 卡顿堆栈采集优化
由于卡顿问题具有暂时性和可恢复性,当检测到卡顿时间超过一定的阀值之后,进行堆栈采集,可能会存在误报的场景,比如下面例子:
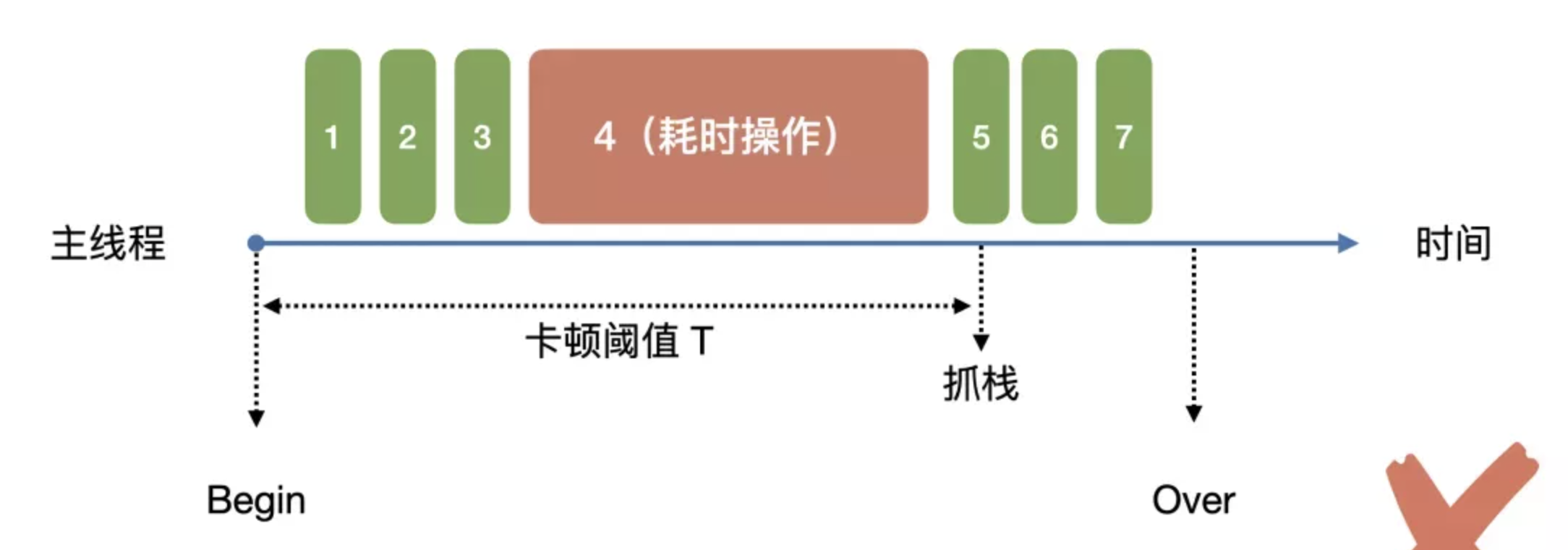
主线程卡顿操作是 4,但由于开始采集堆栈的时间点任务 4 已经执行完成,这时候采集到的是任务 5 的堆栈,上报的任务 5 堆栈并不是真正的卡顿堆栈。
针对这种场景,可以通过采样策略提高堆栈采集的准确性,基本思路就是在常规采集的基础上,在刚发生卡顿的时候,就开始进行堆栈抽样采集,整体实现思路如下:
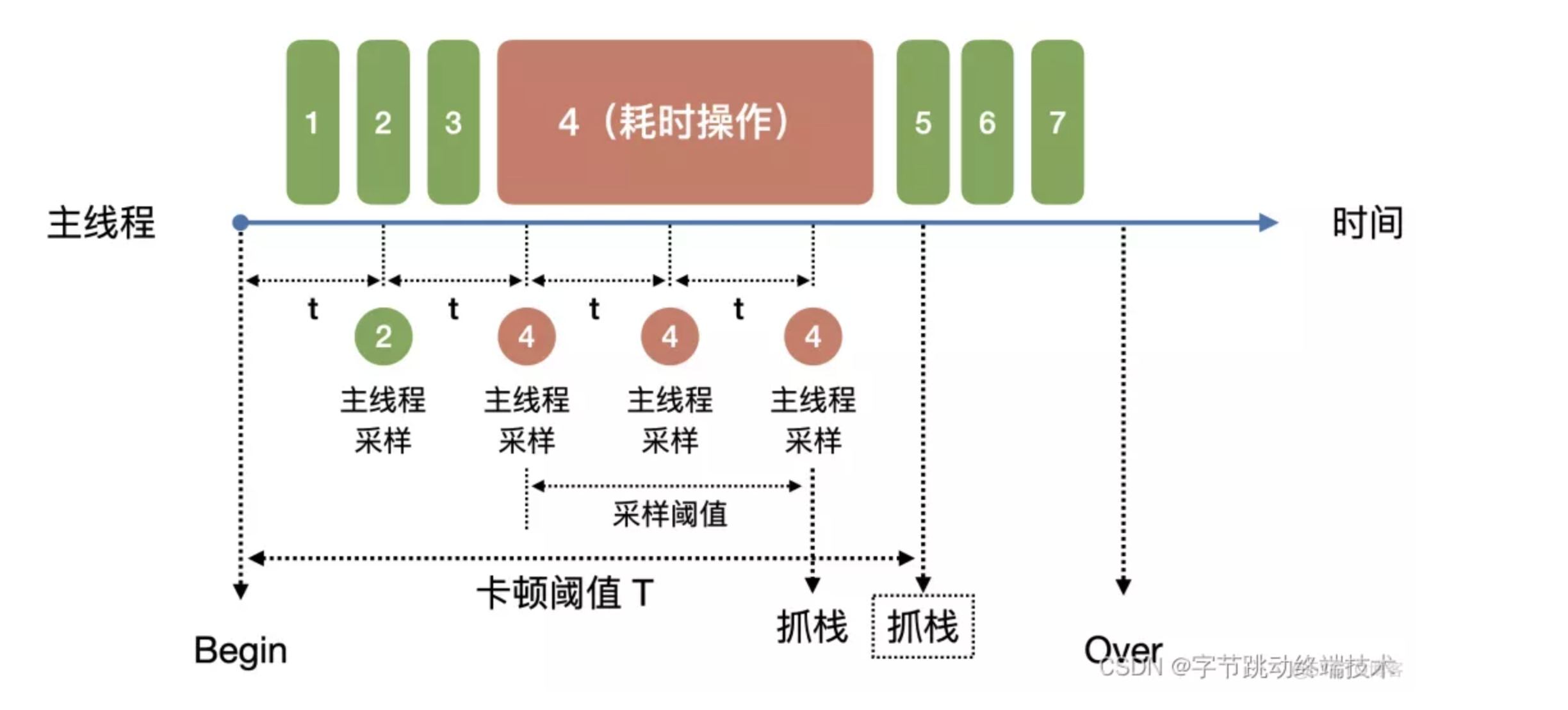
3.2.6 后台卡死误报
后台状态不进行卡顿检查但要进行卡死检测。
参考:后台卡死误报处理
3.2.7 相同卡顿优化 – 退火算法
为了避免同一卡顿问题频繁的检测、堆栈采集和上报。当检测到同一卡顿问题的时候,使用退火算法来降低卡顿检测带来的性能损耗,按照斐波那契数列将检查时间递增直到没有遇到卡顿或者主线程卡顿堆栈不一样。
3.3 主线程消息探测
主线程消息探测原理是向主线程发送一个信号,一定时间内收到了主线程的回复,即表示当前主线程流畅运行。如果没有收到主线程的回复,即表示当前主线程在做耗时运算,发生了卡顿。
主线程消息探测的缺点:比较耗电,因为假如 APP 是处于休眠状态,不间断的消息探测,会不停的唤醒系统和 APP,带来额外的电池消耗。
四、优化建议
4.1 CPU 优化
对象创建
- 轻量对象代替重量对象,不需要响应事件的,用 CALayer 代替 UIView
- 代码创建代替 StoryBoard
- 非 UI 对象放到后台线程创建
- 延迟对象的创建
- 复用对象
对象调整
- CALayer 和 UIView 属性调整消耗资源要大于一般的属性
- 避免调整视图层级,添加或者删除视图,尽可能的使用
hidden属性
对象销毁
- 非 UI 对象放到后台线程去销毁
布局计算和 AutoLayout
- AutoLayout 对于复杂布局存在严重性能问题
- 后台布局计算和布局缓存
文本计算
文本计算,放到后台线程执行:
[NSAttributedString boundingRectWithSize:options:context:]来计算文本宽高[NSAttributedString drawWithRect:options:context:]来绘制文本
文本绘制
- 用 TextKit 或最底层的 CoreText 对文本异步绘制
图片解码
当你用 UIImage 或 CGImageSource 的那几个方法创建图片时,图片数据并不会立刻解码。图片设置到 UIImageView 或者 CALayer.contents 中去,并且 CALayer 被提交到 GPU 前,CGImage 中的数据才会得到解码。这一步是发生在主线程的,并且不可避免。
如果想要绕开这个机制,常见的做法是在后台线程先把图片绘制到 CGBitmapContext 中,然后从 Bitmap 直接创建图片。目前常见的网络图片库都自带这个功能。
图像绘制
图像的绘制通常是指用那些以 CG 开头的方法把图像绘制到画布中,然后从画布创建图片并显示这样一个过程。这个最常见的地方就是 [UIView drawRect:] 里面了。
由于 CoreGraphic 方法通常都是线程安全的,所以图像的绘制可以很容易的放到后台线程进行。一个简单异步绘制的过程大致如下(实际情况会比这个复杂得多,但原理基本一致):
- (void)display {
dispatch_async(backgroundQueue, ^{
CGContextRef ctx = CGBitmapContextCreate(...);
// draw in context...
CGImageRef img = CGBitmapContextCreateImage(ctx);
CFRelease(ctx);
dispatch_async(mainQueue, ^{
layer.contents = img;
});
});
}
4.1.1 图像加载
图片格式对比:
| 格式 | 优点 | 缺点 |
|---|---|---|
| PNG | 解压快 | 加载慢 |
| JPEG | 解压慢 | 加载快 |
图片加载方法对比:
| 方法 | 优点 | 缺点 |
|---|---|---|
+imageNamed: |
立即解压图像,自带缓存 | 只能加载资源束的图像 |
+imageWithContentsOfFile: |
延迟解压图像 | – |
强制解压图像:
-
将图片的一个像素绘制成一个像素大小的 CGContext。这样仍然会解压整张图片,但是绘制本身并没有消耗任何时间。这样的好处在于加载的图片并不会在特定的设备上为绘制做优化,所以可以在任何时间点绘制出来。同样 iOS 也就可以丢弃解压后的图片来节省内存了。
-
将整张图片绘制到 CGContext 中,丢弃原始的图片,并且用一个从上下文内容中新的图片来代替。这样比绘制单一像素那样需要更加复杂的计算,但是因此产生的图片将会为绘制做优化,而且由于原始压缩图片被抛弃了,iOS 就不能够随时丢弃任何解压后的图片来节省内存了。
4.2 GPU 优化
- 尽量减少在短时间内大量图片的显示,尽可能将多张图片合成为一张进行显示
- GPU 能处理的最大纹理尺寸是 4096 * 4096,超过这个尺寸就会占用 CPU 资源,所以纹理不能超过这个尺寸
- 尽量减少视图的数量和层次
- 减少透明的视图(alpha < 1),不透明的就设置
opaque为 YES,透明度涉及到混合颜色的计算 - 尽量避免出现离屏渲染
4.2.1 离屏渲染
CALayer 的边框、圆角、阴影、遮罩(mask),CASharpLayer 的矢量图形显示,通常会触发离屏渲染(offscreen rendering)。
4.2.1.1 离屏渲染原理
图层的叠加绘制大概遵循”画家算法”。
油画算法:先绘制场景中的离观察者较远的物体,再绘制较近的物体。先绘制红色部分,再绘制黄色部分,最后再绘制灰色部分,即可解决隐藏面消除的问题。即将场景按照物理距离和观察者的距离远近排序,由远及近的绘制即可。
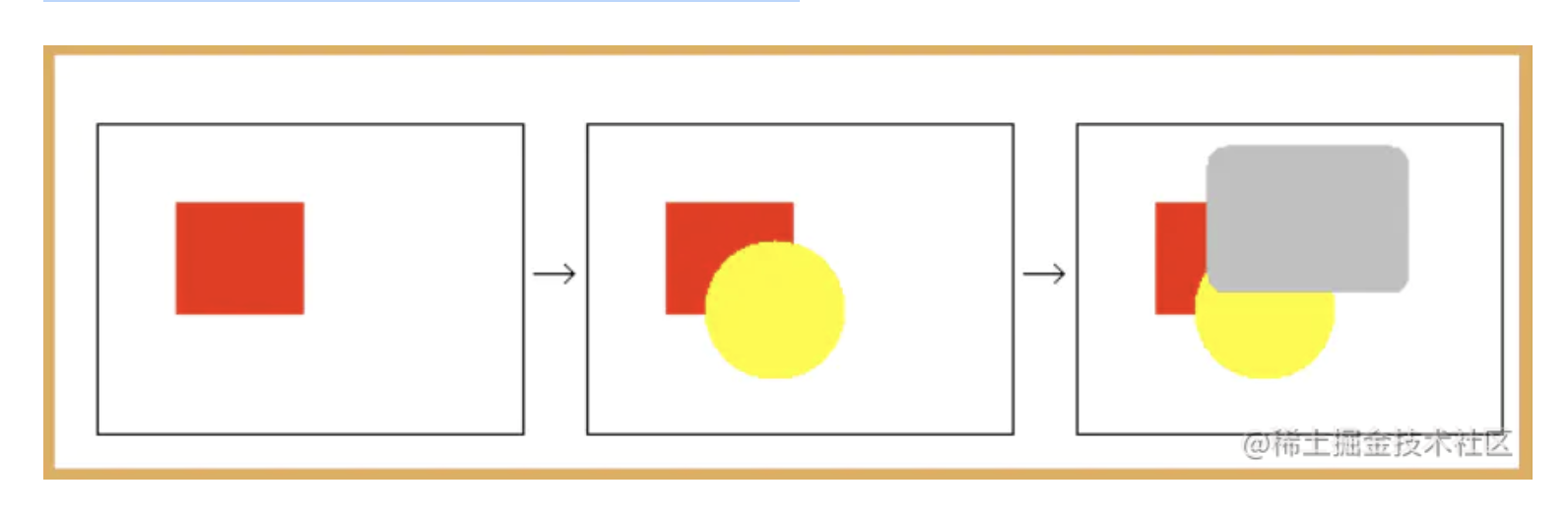
当我们设置了 cornerRadius 以及 masksToBounds 进行圆角+裁剪时,masksToBounds 裁剪属性会应用到所有的图层上。
本来我们从后往前绘制,绘制完一个图层就可以丢弃了。但现在需要依次在 Offscreen Buffer 中保存,等待圆角+裁剪处理,即引发了离屏渲染。
- 背景色、边框、背景色+边框,再加上圆角+裁剪,根据文档说明,因为
contents = nil没有需要裁剪处理的内容,所以masksToBounds设置为 YES 或者 NO 都没有影响。 - 一旦我们为
contents设置了内容,无论是图片、绘制内容、有图像信息的子视图等,再加上圆角+裁剪,就会触发离屏渲染。
4.2.1.2 圆角离屏渲染
cornerRadius + masksToBounds 不一定会触发离屏渲染,添加 contents 会触发离屏渲染,或者为视图添加一个有颜色、内容或边框等有图像信息的子视图也会触发离屏渲染。
关于圆角,iOS 9 及之后的系统版本,苹果进行了一些优化。我们只设置 contents 或者 UIImageView 的 image,并加上圆角+裁剪,是不会产生离屏渲染的。但如果加上了背景色、边框或其他有图像内容的图层,还是会产生离屏渲染。
4.3 高效绘图
- 避免软件绘图
- 使用 CAShapeLayer 进行矢量图形绘制
- 只触发脏矩形绘制
- 使用 CATiledLayer 进行异步绘制
shouldRasterize自带缓存作用,要避免作用在内容不断变动的图层上,否则它缓存方面的好处就会消失,而且会让性能变的更糟- 如果没有自定义绘制的任务就不要在子类中写一个空的
-drawRect:方法,因为系统会为视图分配一个寄宿图,这个寄宿图的像素尺寸等于视图大小乘以contentsScale的值,造成 CPU 浪费
五、优化案例
5.1 网络操作放到非主线程

5.2 渲染卡顿

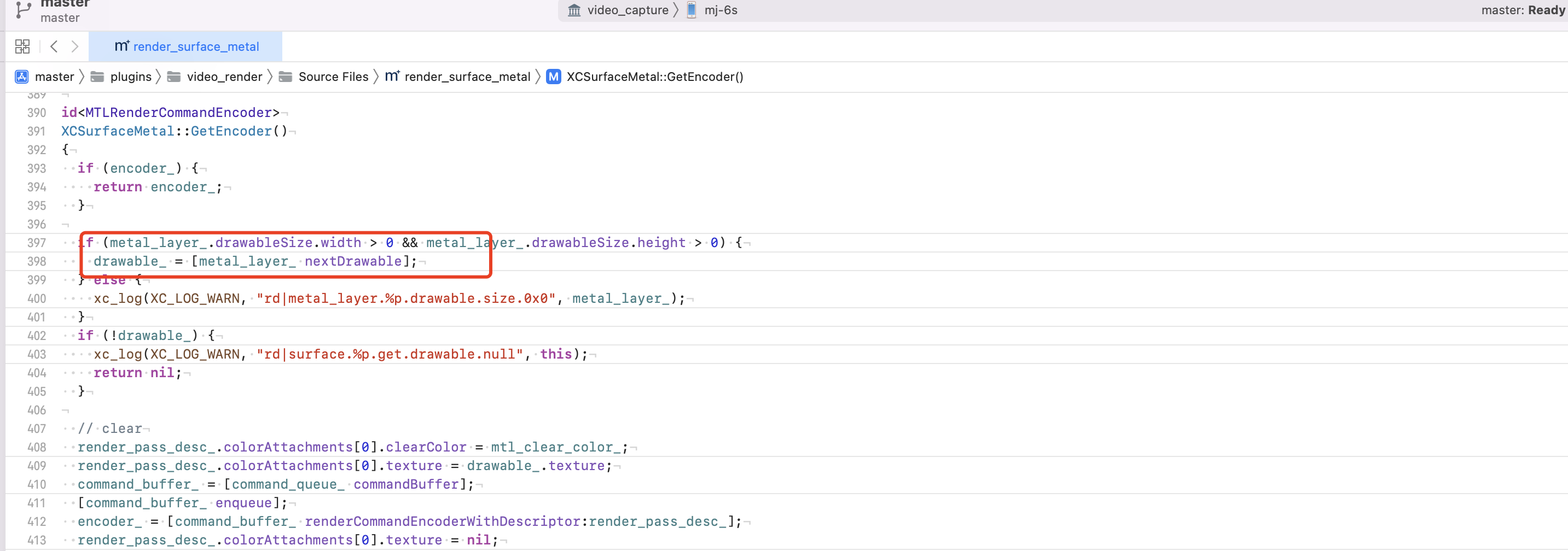
问题说明:nextDrawable 从对象池获取 CAMetalDrawable,当目标没有空余的 Drawable 的时候,主线程就会被阻塞。